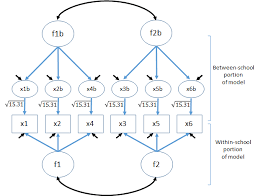
This course is designed as an introduction to the concepts and techniques required to analyse data that is multi-level in nature. (That is, data that is derived from subjects who are nested within groups or data that involves repeated measures that are nested within subjects)
This is the 2nd Multi-level Analysis using Mplus course for Summer 2021.
All course material will be covered in 4 days, with longer days.
*This course will be run over 4 days, (Wed-Friday + following Monday) in three sessions per day:
- 10.00am - 12.00pm - Session 1
- 1.00pm - 2.30pm - Session 2
- 3.00pm - 4.30pm - Session 3
Exercises will be provided, and 20-30 minute individual consultation sessions can be scheduled for each participant by appointment.
*Courses will run on Australian Eastern Daylight Time (GMT +11)
(ie Melbourne, Sydney, Canberra daylight savings time. There will be 5 different time zones to consider in Summer)

Mr Philip Holmes-Smith (OAM) is the Director of School Research, Evaluation and Measurements Services (SREAMS), an independent educational research consultancy business. His research, evaluation and measurement interests lie in the areas of teacher effectiveness and school improvement, accountability models and benchmarking, improving the quality of teaching, using student performance data to inform teaching, and large-scale achievement testing programs. He is an experienced teacher of social science research methods and is a regular instructor at the ACSPRI programs. He also regularly teaches Structural Equation Modeling (SEM) and Multi-Level Analysis (MLA) at various universities around Australia.
In conventional regression analysis it is assumed that subjects are randomly selected and, therefore, all the variance in your dependent variables is due solely to variation amongst individuals. However, in most studies, subjects are clustered within a group and multiple groups are sampled. For example, in an education study, we may have students clustered within multiple classes; in a human resourcing study, we may have employees clustered within multiple work units or teams. In such sampling, although some of the variance in your dependent variables will be due to variation amongst individuals, some the variance in your dependent variables will also be due to variation amongst the groups themselves. In such cases, multilevel analysis (MLA) should be employed to account for the different levels of variation.
Repeated measure designs should also be analysed using multilevel analysis because the repeated observations are nested within subjects. For example, in a marketing study, we may have repeated measures of consumers’ attitudes to a brand over the life of a marketing campaign; in an epidemiology study, we may have repeated measures of a health outcome over the life of a drug treatment regime. In such studies, although some of the variance in your dependent variables will be due to variation across the various time occasions, some the variance in your dependent variables will also be due to variation amongst individuals themselves. Again, in such cases, multilevel analysis (MLA) should be employed to account for the different levels of variation.
This course is designed to take participants from an introductory level up to an intermediate level of multilevel analysis. That is, the course assumes that participants have had no prior experience with multilevel modeling, (or have only a basis understanding), and takes participants through the basics up to an intermediate level. Although there are several programs that can be used to conduct multilevel analysis, in this course we will use the Mplus program.
Detailed notes with worked examples and references will be provided as a basis for both the lecture and hands-on computing aspect of the course.
The target audience for this course is researchers needing to learn how to analyse data that has been collected through a hierarchical (or clustered) sampling approach using the Mplus software.
Day 1
Introduction to multilevel data, revision of basic analytical techniques and an introduction to multilevel modeling. This part of the course describes the nature of multilevel data, introduces the Mplus programming language by revising basic single-level regression models and basic single-level confirmatory factor analysis, and introduces to principals and nomenclature of multilevel modeling. We will note the difference between the conventional (single-level) regression approach and the multilevel regression approach, we will highlight the dangers of not treating nested data as multilevel data, and we will discuss the advantages of multilevel analysis.
Day 2
Two-level regression models. These models investigate two-level research questions, where subjects are nested within groups and explanatory (independent) variables have been measured at the subject level (Level 1) and/or the group level (Level 2). For example, in education, our outcome variable may be “reading comprehension” and we could regress this outcome on both Level 1 independent variables, (e.g. the student’s verbal reasoning skills, their motivation to learn, etc.), and Level 2 independent variables (e.g. the teachers experience, the average ability of all students within the class, etc.). In each example we will build models from the simplest variance component model to investigating random intercepts and finally, random slopes.
Day 3
Two-level latent growth-curve models (repeated measure designs): These models investigate change over time and enable the researcher to describe how an outcome (dependent) variable is improving or declining across a number of repeated measures. For example, in marketing we may be interested in analysing consumers’ attitudes to a brand over the life of a marketing campaign. The repeated measure (attitudes) may improve as a function of time, but different marketing techniques (a time varying independent variable), may also influence the rate of improvement. Both linear and non-linear growth will be investigated.
Day 4
Two-level confirmatory factor analysis (CFA) and structural equation modeling (SEM): These models introduce latent variables into the multilevel modeling framework. In multilevel CFA models, the dependent variable is a factor (rather than an observed variable). Such models may or may not contain observed explanatory variables. In multilevel SEM the independent variable(s) is/are a factor (rather than an observed variable). Such models may contain observed and/or latent dependent variables.
Three-level Models. These models investigate three-level research questions where subjects are either nested within sub-groups and sub-groups are nested within higher level groups or repeated measures are nested within subjects who, in turn, are nested within groups. Now, not only are the explanatory (independent) variables measured at the subject level (Level 1) and/or the sub-group level (Level 2) but they may also be measured at a third level (e.g. multiple students nested within multiple classes, multiple classes nested in multiple schools).
Day 5
Mixture Modeling (including Latent Class Analysis). Mixture models are similar to Multilevel models in that patterns in the data vary across different groups. The difference, however, is that group membership is determined by the data, not some a priori allocation to groups. Cross-sectional models include Mixture regression analysis; Latent Class Analysis (LCA); CFA mixture modeling; and Structural equation mixture modeling. Longitudinal models include Growth Mixture Modeling (GMM) for a continuous outcome; and Latent Class Growth Analysis (LCGA) for a binary, ordinal or count outcome.
Consultations. During the course, Phil will make appointments with participants who want help with their own research problems. These appointments will be scheduled either before, between or after instruction time on the last two days of the course.
Training in this course will be for 5 hours per day over Zoom.
Questions are encouraged.
Individual consultation sessions will be for 20-30 minutes for each participant by appointment.
No prior knowledge of multilevel analysis is required nor is it assumed that participants have had experience with Mplus – the Mplus programming language will be taught as part of the course. However, it is assumed that all participants will have a thorough understanding of regression analysis and factor analysis. Furthermore, it is assumed that all participants have completed a course in Structural Equation Modeling (SEM) or have had equivalent SEM experience.
The instructor's bound, book length course notes will serve as the course texts.
These will be posted in advance to your supplied 'shipping address'.
Other references include:
- Muthén, L.K. and Muthén, B.O. (1998-2017). Mplus User’s Guide. Eighth Edition. Los Angeles, CA: Muthén & Muthén.
- Snijders, Tom A.B. and Bosker, Roel J. (2012). Multilevel Analysis: An Introduction to Basic and Advanced Multilevel Modeling. (2nd Ed.). London: Sage Publications
- Kline, Rex B. (2016). Principles and Practice of Structural Equation Modeling (4th Ed.). New York: Guilford Press.
Q: Do I have to have to know anything about Multilevel Analysis before attempting the course?
A: No prior knowledge of multilevel analysis is required nor is it assumed that participants have had experience with Mplus.
Both the immediate benefits from the course, (learning delivered from lecturers) and the delayed benefits from provided resources, will assist in developing robust statistical models for work and academic purposes. (Summer 2020)
It was to the point and not overly simplistic not too difficult. there was enough room for individuals needs. (Summer 2020)
It helped clarify a few things for my research & showed me how to things in a very methodical way, so for that I’m very grateful :) (Summer 2019)
Systematic development of knowledge and skills (Summer 2019)
I learnt new things, but I also have corrected and advanced previous knowledge! It was great & challenging! (Summer 2017)
More advanced knowledge on the topic - and particularly a different perspective. Understood some new concepts that I’d had trouble grasping when taught previously. (Summer 2015)
It was not only helpful so far as the specific course content was concerned but also so far as all the additional material & background revision was concerned (eg. reviewing regression analysis & explanatory & confirmatory factor analysis dealing with mis (Summer 2015)
The instructor is very patient and he responds to every question very well. (Winter 2014)
The instructor's bound, book length course notes will serve as the course texts.
These will be posted in advance to your supplied 'shipping address'.
